Data Builder
Archie Core Data Builder to interfejs modelowania danych służący do definiowania tabel bazy danych, typów pól i relacji między tabelami.
Aby otworzyć Data Builder, kliknij Data Model (Model Danych) na pasku bocznym, wybierz tabelę, nad którą chcesz pracować, a następnie kliknij zakładkę Schema (Schemat).
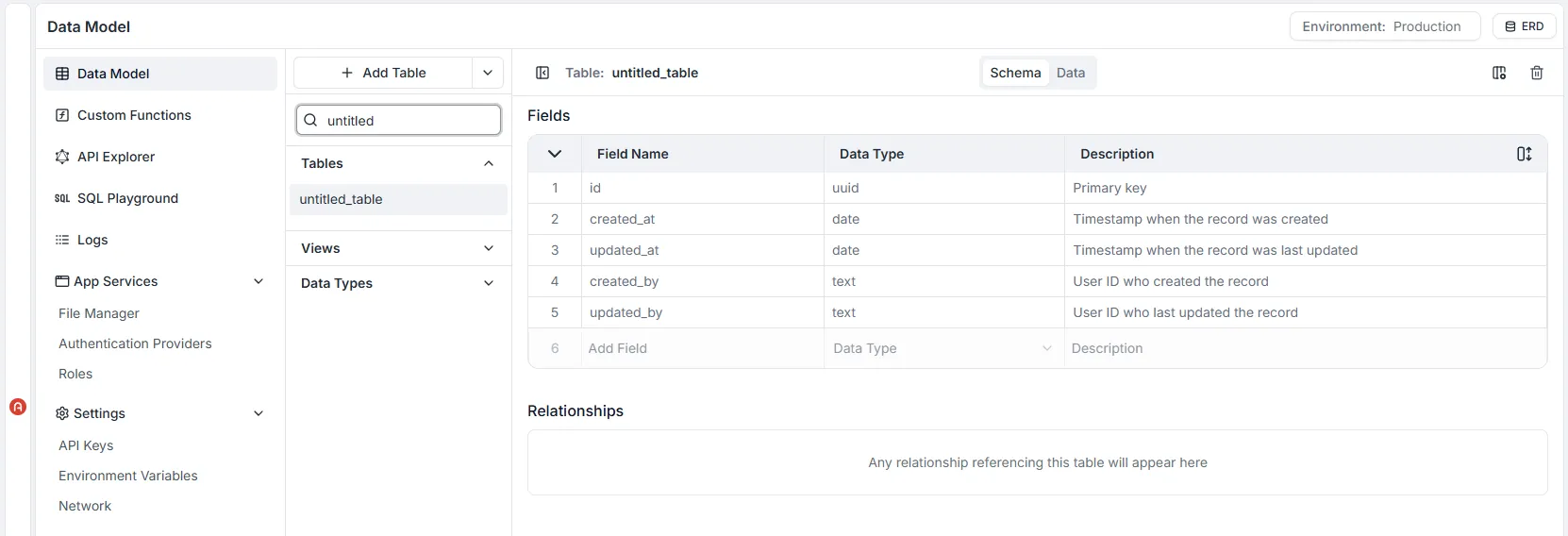
Dla każdej zdefiniowanej tabeli silnik GraphQL Archie Core automatycznie tworzy typy obiektów schematu GraphQL oraz odpowiadające im pola zapytań (query), mutacji (mutation) i subskrypcji (subscription) wraz z resolverami.
Oznacza to, że wszystkie działania Twórz (Create), Czytaj (Read), Aktualizuj (Update) i Usuń (Delete) (CRUD), a także połączenia w czasie rzeczywistym (websockets), są natychmiast dostępne do użycia za pośrednictwem unikalnego punktu końcowego API obszaru roboczego.
Praca z Tabelami
Dział zatytułowany „Praca z Tabelami”W tle Archie Core udostępnia dedykowaną instancję bazy danych PostgreSQL dla Twojego obszaru roboczego. PostgreSQL to zaawansowana relacyjna baza danych obiektowa o otwartym kodzie źródłowym, znana ze swojej niezawodności i integralności danych. Wydajnie obsługuje złożone zapytania i w pełni wspiera zgodność z ACID (Atomowość, Spójność, Izolacja, Trwałość).
Tworzenie Tabel
Dział zatytułowany „Tworzenie Tabel”Kliknij przycisk + Add Table (+ Dodaj Tabelę), aby utworzyć nową tabelę. Domyślna nazwa dla nowych tabel to “untitled_table”. Wszystkie tabele wymagają unikalnych nazw (nazwy attribute, workspace i ich liczba mnoga są zastrzeżone i nie mogą być używane w żadnej wielkości liter).
Po utworzeniu tabeli, odpowiadające jej typy schematu GraphQL oraz resolvery zapytań, mutacji i subskrypcji zostaną wygenerowane automatycznie.
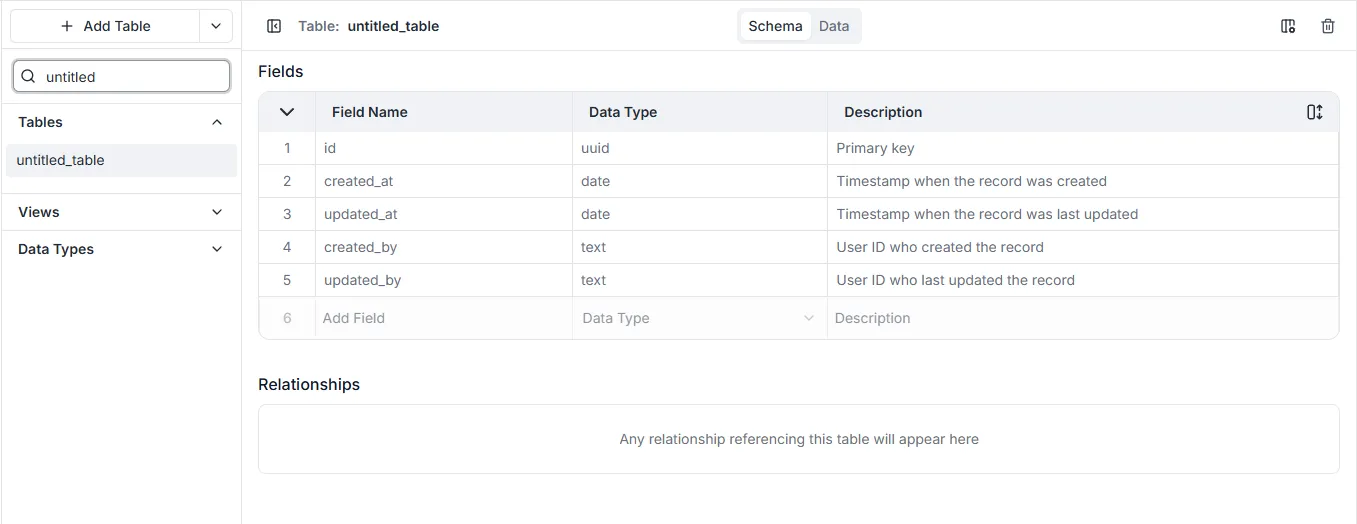
Aktualizowanie Tabel
Dział zatytułowany „Aktualizowanie Tabel”Po utworzeniu tabeli można zdefiniować pola i relacje. Wszystkie aktualizacje tabeli są publikowane w czasie rzeczywistym, zapewniając płynne przejście między definiowaniem modelu danych a jego wysoką dostępnością.
Po aktualizacji tabeli, odpowiadające jej typy schematu GraphQL oraz resolvery zapytań, mutacji i subskrypcji zostaną zaktualizowane automatycznie.
Aby zminimalizować błędy związane z tabelami, Archie Core chroni przed wieloma szkodliwymi działaniami. Niektóre z nich to:
- Monit wymagający podania Default Value (Wartości Domyślnej) pojawi się przy zmianie pola nieobowiązkowego na obowiązkowe.
- Wartości pól Data, Liczba i Tekst są automatycznie konwertowane, gdy aktualizowany jest istniejący typ pola.
- Przy zmianie pola nieunikalnego na unikalne, bieżące rekordy są sprawdzane pod kątem unikalnych wartości.
Usuwanie Tabel
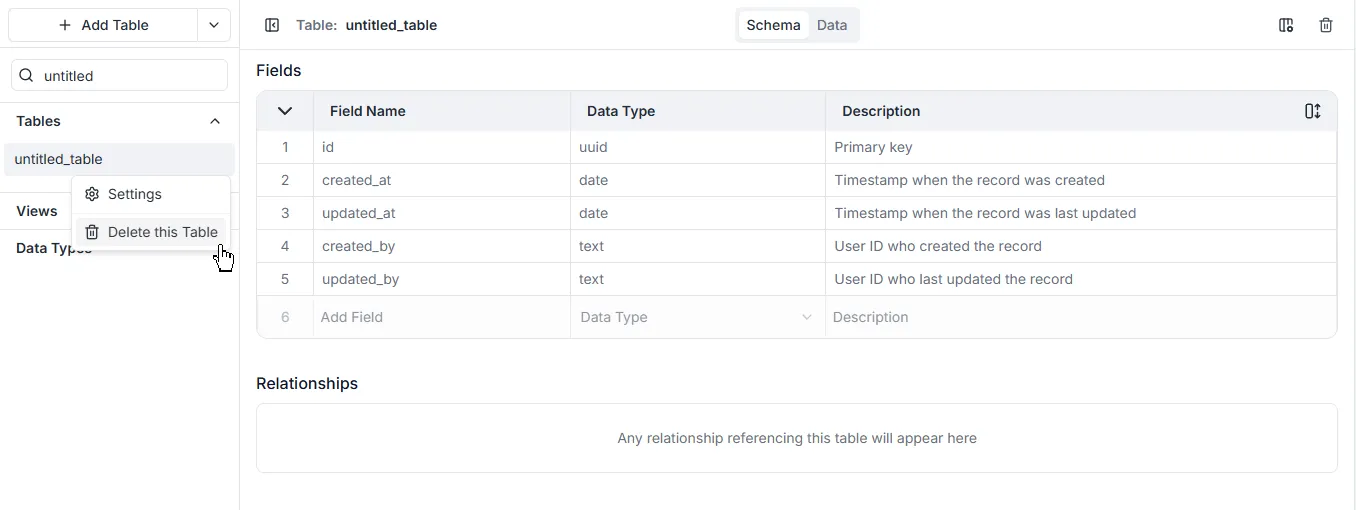
Dział zatytułowany „Usuwanie Tabel”Aby usunąć tabelę:
- Przejdź do nazwy tabeli i kliknij
... - Kliknij Delete this Table (Usuń tę Tabelę).
- Otworzy się okno dialogowe potwierdzenia. Wpisz nazwę tabeli i kliknij Delete (Usuń).
Niebezpieczeństwo: Usunięte tabele nie mogą zostać przywrócone, a wszelkie istniejące rekordy tabeli zostaną utracone. Ponadto, jeśli istnieją tabele powiązane z usuwaną tabelą - belongs to (należy do) i has many (ma wiele), określone jako obowiązkowe lub nie - te relacje zostaną zerwane.
Relacje Tabel
Dział zatytułowany „Relacje Tabel”Archie Core obsługuje definiowanie trzech typów relacji tabel, które są zgodne z tym, czego można oczekiwać od relacyjnych baz danych:
| Typ | A do B | B do A |
|---|---|---|
| jeden-do-jednego | Rekordy w tabeli A mogą mieć have_one (jeden) lub belong_to (należeć do) rekordu w tabeli B. | Rekordy w tabeli B mogą mieć have_one (jeden) lub belong_to (należeć do) rekordu w tabeli A. |
| jeden-do-wielu | Rekord w tabeli A może mieć have_many (wiele) rekordów w tabeli B. | Rekordy w tabeli B mogą mieć have_one (jeden) lub belong_to (należeć do) rekordu w tabeli A. |
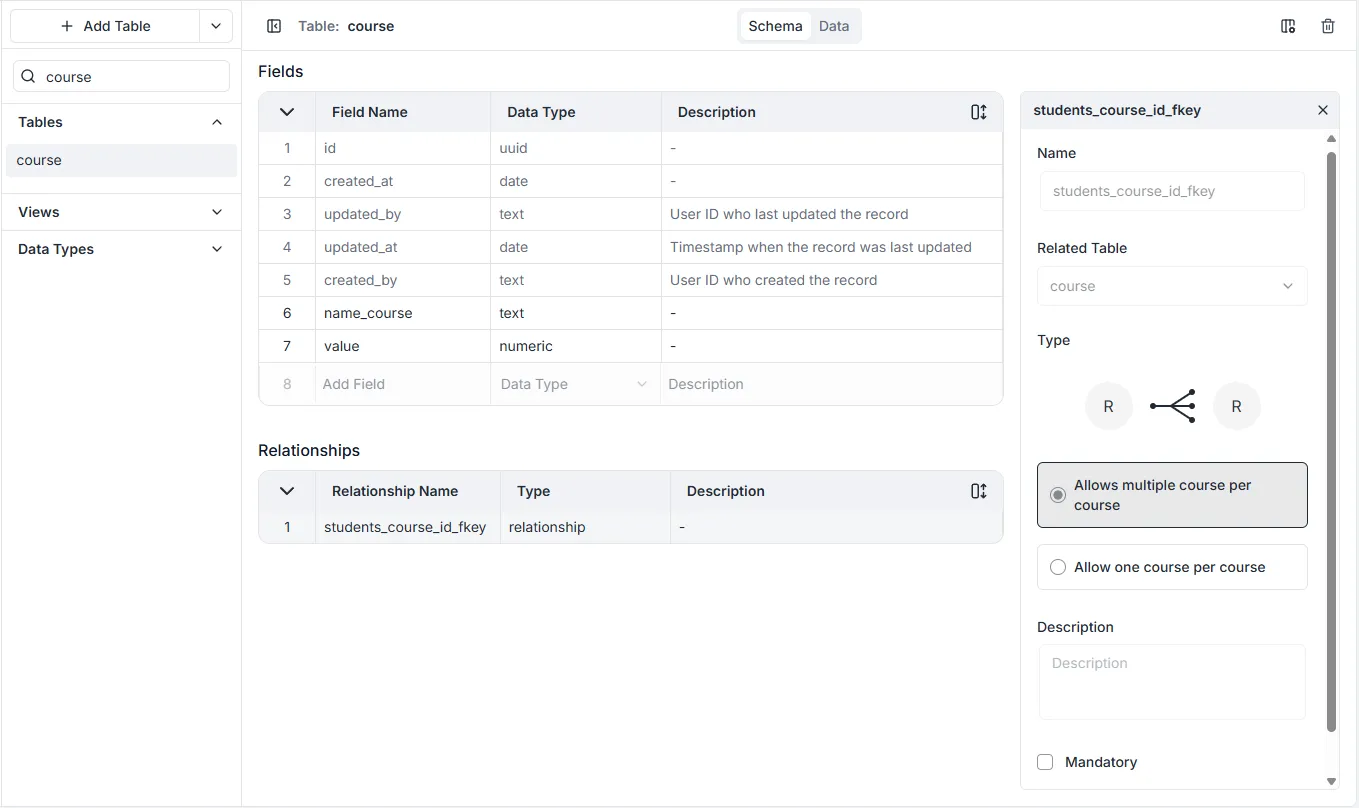
Zdefiniowanie relacji między dwiema tabelami można osiągnąć, przeciągając i upuszczając jedną tabelę na drugą lub wybierając Table (Tabela) jako Typ Danych podczas tworzenia nowego pola tabeli.
Konfiguracje Tabeli
Dział zatytułowany „Konfiguracje Tabeli”Aby określić relacje has many (ma wiele), has one (ma jeden) i belongs to (należy do) między tabelami.
Konfiguracje
- Name: Aby wybrać, która tabela ma być powiązana.
- Related Table: Nazwa relacji, jak pojawia się w odpowiedniej tabeli.
- Type: Czy relacja to has one (ma jeden) czy has many (ma wiele).
- Description: Opcjonalne pole tekstowe, w którym możesz wpisać informacje o polu.
- Mandatory: Czy relacja pola jest wymagana.
Typy Tabel
Dział zatytułowany „Typy Tabel”Istnieją trzy typy tabel: Niestandardowa (Custom), Widok (View) i Typ Danych (Data Type).
Tabele Niestandardowe
Dział zatytułowany „Tabele Niestandardowe”Tabele niestandardowe to tabele utworzone w dowolnym obszarze roboczym przez administratora. Są w pełni konfigurowalne.
Tabele Widoków
Dział zatytułowany „Tabele Widoków”Tabele widoków to tabele wirtualne, które agregują pola z wielu tabel w jeden widok. “Pod maską” są one oparte na zestawie wyników instrukcji SQL. W obszarze roboczym można je tworzyć za pomocą mutacji GraphQL viewCreate w API Explorer.
Typ Danych
Dział zatytułowany „Typ Danych”Typy pozwalają zdefiniować statyczny, uporządkowany zestaw wzajemnie wykluczających się wartości. W przeciwieństwie do standardowych pól tekstowych, typ Enum ogranicza wprowadzanie danych do określonej listy predefiniowanych stałych.
Typowe przykłady to wskaźniki statusu (np. SZKIC, OPUBLIKOWANY, ZARCHIWIZOWANY), role użytkowników lub etykiety kategorii.
Użyteczność i Korzyści
Dział zatytułowany „Użyteczność i Korzyści”Używanie typów Enum w schemacie bazy danych oferuje kilka kluczowych korzyści:
- Integralność Danych: Enums wymuszają ścisłą walidację danych na poziomie bazy danych. Ponieważ pole akceptuje tylko wartości ze zdefiniowanej listy, eliminuje to błędy spowodowane literówkami lub niespójnymi konwencjami nazewnictwa (np. zapobieganie mieszance “Wysoki”, “wysoki” i “Wys” dla pola priorytetu).
- Spójność Kodu: Zapewniają jedno źródło prawdy dla dozwolonych wartości, dzięki czemu logika aplikacji jest bardziej przewidywalna i łatwiejsza w utrzymaniu.
- Czytelność: Enums sprawiają, że dane są samopisujące. Wartość taka jak
PLATNOSC_NIEUDANAjest znacznie bardziej znacząca dla programistów i analityków niż arbitralny kod numeryczny, taki jakkod_bledu: 3. - Wydajność: W PostgreSQL typy Enum są przechowywane wydajnie “pod maską”, ale prezentowane jako czytelne ciągi znaków, oferując równowagę między wydajnością a czytelnością dla człowieka.